try-regex
A repository to work on regular expressions of different programming languages(basically Python, JavaScript, Golang etc.), trying different samples as per the need based on different requirements.




You can also visit https://hygull.github.io/try-regex/ to see colored beautiful documentation of this same age.
Note: Here you can find examples from too simple to advanced as the purpose of this repository is to learn and earn knowledge step by step. So, please don’t think too much if somewhere I expanded 1 line code to 2 or more.
Contents
Python - List of functions/methods used in examples presented below
Basic functions/methods
-
sub()
-
compile()
-
findall() - a method defined on pattern object. For more details, check this.
-
match()
-
finditer() - a method which returns an iterator
Other functions/methods
-
start() - a method defined on match object
-
end() - a method defined on match object
-
span() - a method defined on match object
Getting started - Python's regular expressions
- Open Python3 terminal and list out all the packages of re module.
Python 3.6.7 (v3.6.7:6ec5cf24b7, Oct 20 2018, 03:02:14)
[GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
>>> import re
>>>
>>> dir(re)
['A', 'ASCII', 'DEBUG', 'DOTALL', 'I', 'IGNORECASE', 'L', 'LOCALE', 'M', 'MULTILINE', 'RegexFlag', 'S', 'Scanner', 'T', 'TEMPLATE', 'U', 'UNICODE', 'VERBOSE', 'X', '_MAXCACHE', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '__version__', '_alphanum_bytes', '_alphanum_str', '_cache', '_compile', '_compile_repl', '_expand', '_locale', '_pattern_type', '_pickle', '_subx', 'compile', 'copyreg', 'enum', 'error', 'escape', 'findall', 'finditer', 'fullmatch', 'functools', 'match', 'purge', 'search', 'split', 'sre_compile', 'sre_parse', 'sub', 'subn', 'template']
>>>
- Here we don’t know which are callable and which are constants/variables. Have a look at the below error by assuming that re.A is a callable.
>>> re.A()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'RegexFlag' object is not callable
>>>
>>> re.A
<RegexFlag.ASCII: 256>
>>>
- Finding list of all callables.
Here, in the below example you can see re.A is not a callable.
>>> for item in dir(re):
... if callable(getattr(re, item)):
... print(item)
...
RegexFlag
Scanner
_compile
_compile_repl
_expand
_pattern_type
_pickle
_subx
compile
error
escape
findall
finditer
fullmatch
match
purge
search
split
sub
subn
template
>>>
- Retrieving all integers from text - Using sub() (replacement) function
>>> import re
>>>
>>> text = "These 2 days, I will do 8 imp tasks for 100 years to make $200 using 90 techniques."
>>> nums = re.sub(r"\D+", '', text)
>>> nums
'2810020090'
>>>
>>> nums = re.sub(r"\D+", ' ', text) # PERFECT
>>> nums
' 2 8 100 200 90 '
>>>
>>> nums = nums.strip() # REMOVE spaces around
>>> nums
'2 8 100 200 90'
>>>
>>> nums = nums.split()
>>> nums
['2', '8', '100', '200', '90']
>>>
>>> nums = map(int, nums)
>>> nums
<map object at 0x103a45160>
>>>
>>> nums = list(nums)
>>> nums
[2, 8, 100, 200, 90]
>>>
>>> sum(nums) # SUM OF INTEGERS
400
>>>
- Retrieving all integers from text - Using compile() function & findall() method
>>> text = "These 2 days, I will do 8 imp tasks for 100 years to make $200 using 90 techniques."
>>>
>>> p = re.compile(r"\d+")
>>>
>>> p.findall(text)
['2', '8', '100', '200', '90']
>>>
>>> nums = [int(num) for num in p.findall(text)]
>>> nums
[2, 8, 100, 200, 90]
>>>
- Retrieving all integers from text - Using compile() function & finditer() method
>>> text = "These 2 days, I will do 8 imp tasks for 100 years to make $200 using 90 techniques."
>>>
>>> p = re.compile(r"\d+")
>>>
>>> iterator = p.finditer(text)
>>>
>>> match1 = iterator.__next__()
>>> match1.span()
(6, 7)
>>> text[6: 7]
'2'
>>>
>>> match2 = iterator.__next__()
>>> match2.span()
(24, 25)
>>> text[24: 25]
'8'
>>>
>>> match3 = iterator.__next__()
>>> match3.span()
(40, 43)
>>>
>>> text[40: 43]
'100'
>>>
>>> match4 = iterator.__next__()
>>> match4.span()
(59, 62)
>>> text[59: 62]
'200'
>>>
>>> match5 = iterator.__next__()
>>> match5.span()
(69, 71)
>>> text[69: 71]
'90'
>>>
>>> match6 = iterator.__next__() # Exception
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>>
>>> match1.start()
6
>>> match1.end()
7
>>> match2.end()
25
>>> match2.start()
24
>>>
Let’s use above in better way.
>>> text = "These 2 days, I will do 8 imp tasks for 100 years to make $200 using 90 techniques."
>>>
>>> p = re.compile(r"\d+")
>>>
>>> iterator = p.finditer(text)
>>>
>>> nums = []
>>>
>>> for match in iterator:
... start, end = match.start(), match.end()
... nums.append(int(text[start: end]))
...
>>> nums
[2, 8, 100, 200, 90]
>>>
- Removing multiple underscores to get Python like variable names
>>> import re
>>>
>>> text = "full____name_"
>>> output = re.sub(r"_+", '_', text.strip("_")).lower()
>>> output
'full_name'
>>>
>>> text = "___is__to__old___"
>>> output = re.sub(r"_+", '_', text.strip("_")).lower()
>>> output
'is_to_old'
>>>
>>> text = "___iS__Too__OLD"
>>> output = re.sub(r"_+", '_', text.strip("_")).lower()
>>> output
'is_too_old'
>>>
Better way
re.sub(r"_{2,}", '_', text.strip("_")).lower()
>>> text = "Python_____is__really___great__for__all__"
>>>
>>> output = re.sub(r"_+", '_', text.strip("_")).lower()
>>> output
'python_is_really_great_for_all'
>>>
>>> output2 = re.sub(r"_{2,}", '_', text.strip("_")).lower()
>>> output2
'python_is_really_great_for_all'
>>>
>>> output3 = re.sub(r"_{3,}", '_', text.strip("_")).lower()
>>> output3
'python_is__really_great__for__all'
>>>
- Showing only words from any sentence (removing all numbers, limiting 2+ spaces to 1)
>>> import re
>>>
>>> text = "12 coins were on 5 tables for 7 days."
>>>
>>> arr = re.split(r"\d+", text)
>>> arr
['', ' coins were on ', ' tables for ', ' days.']
>>>
>>> ''.join(arr)
' coins were on tables for days.'
>>>
>>> ''.join(arr).strip()
'coins were on tables for days.'
>>>
>>> re.sub(r'\s+', ' ', ''.join(arr).strip())
'coins were on tables for days.'
>>>
- A simple camel case conversion to underscored case
>>> import re
>>>
>>> text = "MyFullName"
>>>
>>> p = re.compile("[A-Z]")
>>>
>>> iterator = p.finditer(text)
>>> i = 0
>>> output = ''
>>> for match in iterator:
... if i == 0:
... start, end = match.start(), match.end()
... else:
... start2, end2 = match.start(), match.end()
... output += text[start: start2].lower() + ":"
... start = start2
... i += 1
... else:
... output += text[start2:].lower()
...
>>> output
'my:full:name'
>>>
>>> re.sub(r':', '_', output)
'my_full_name'
>>>
Getting started - JavaScript's regular expressions
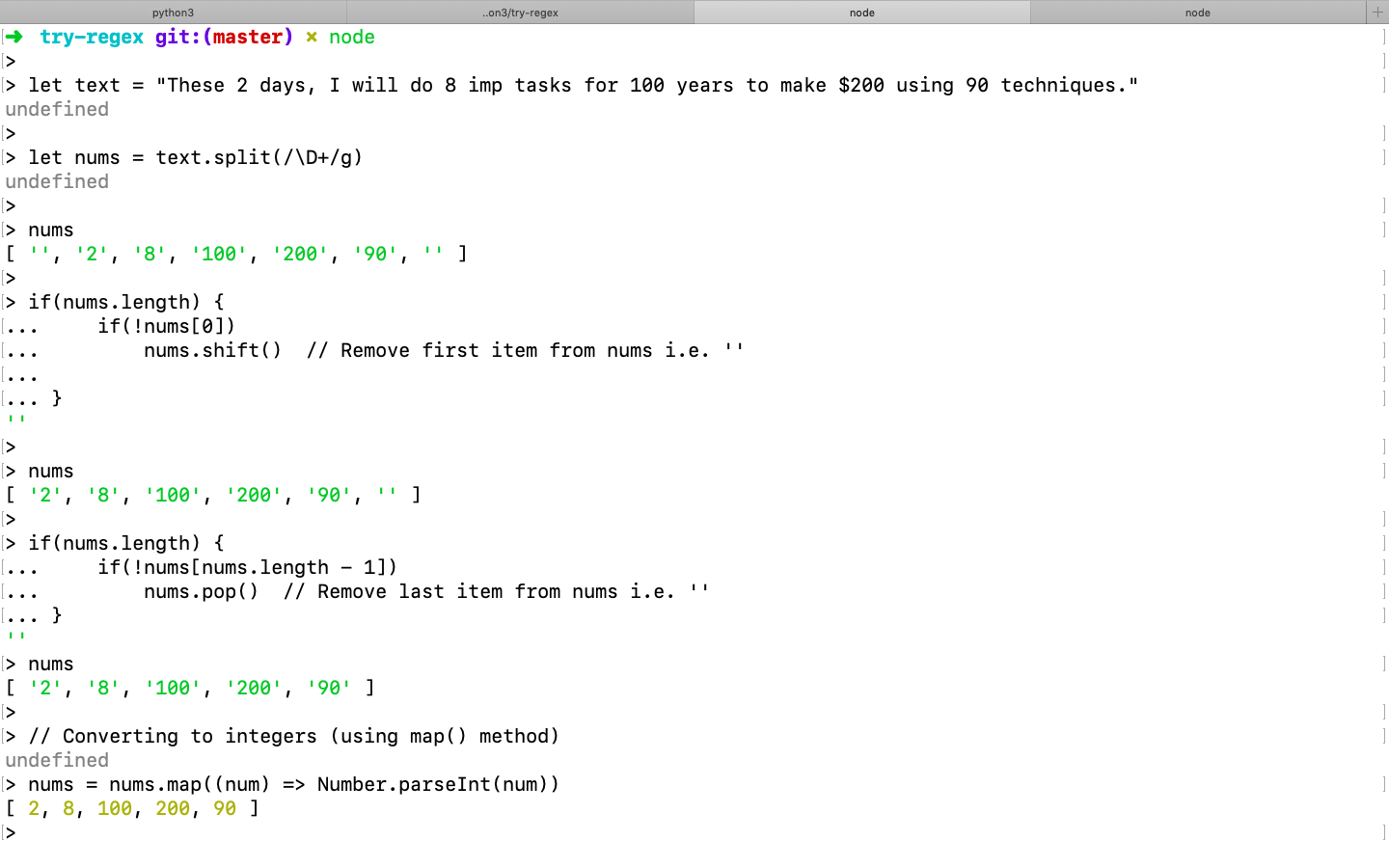
- Retrieving all integers from text (use of
split(),shift(),pop(),map()methods)
➜ try-regex git:(master) ✗ node
>
> let text = "These 2 days, I will do 8 imp tasks for 100 years to make $200 using 90 techniques."
undefined
>
> let nums = text.split(/\D+/g)
undefined
>
> nums
[ '', '2', '8', '100', '200', '90', '' ]
>
> if(nums.length) {
... if(!nums[0])
... nums.shift() // Remove first item from nums i.e. ''
...
... }
''
>
> nums
[ '2', '8', '100', '200', '90', '' ]
>
> if(nums.length) {
... if(!nums[nums.length - 1])
... nums.pop() // Remove last item from nums i.e. ''
... }
''
> nums
[ '2', '8', '100', '200', '90' ]
>
> // Converting to integers (using map() method)
undefined
> nums = nums.map((num) => Number.parseInt(num))
[ 2, 8, 100, 200, 90 ]
>
> nums
[ 2, 8, 100, 200, 90 ]
>
Attached screenshot
- Retrieving integers from text (use of
split(),trim(),replace(),map()methods)
> let text = "These 2 days, I will do 8 imp tasks for 100 years to make $200 using 90 techniques."
undefined
>
> text.replace(/\D+/g, ' ')
' 2 8 100 200 90 '
>
> text.replace(/\D+/g, ' ').trim()
'2 8 100 200 90'
>
> text.replace(/\D+/g, ' ').trim().split(' ')
[ '2', '8', '100', '200', '90' ]
>
> text.replace(/\D+/g, ' ').trim().split(' ').map((num) => Number.parseInt(num))
[ 2, 8, 100, 200, 90 ]
>